<< Hide Menu
Jed Quiaoit
Samantha Himegarner
Jed Quiaoit
Samantha Himegarner
Skills you’ll gain in this topic:
- Describe translation and the roles of mRNA, tRNA, and ribosomes.
- Explain how the genetic code specifies amino acid sequences.
- Predict how mRNA sequence mutations affect protein structure.
- Relate translation stages to protein synthesis efficiency.
- Analyze translation errors’ effects on cellular function.
Central Dogma, Continued: RNA to️ Polypeptide Chain
Translation is the process by which the genetic information encoded in mRNA is used to synthesize a polypeptide, which is a chain of amino acids that form a protein. This process occurs on ribosomes, which are complex molecular machines made up of proteins and RNA. 🎰
In prokaryotic cells, ribosomes are found floating freely in the cytoplasm. In eukaryotic cells, ribosomes are also present in the cytoplasm, but a significant portion of protein synthesis also occurs on the rough endoplasmic reticulum (RER), a network of flattened sacs and tubules that is studded with ribosomes on its outer surface.
During translation, the mRNA is first bound to the ribosome and then read in groups of three nucleotides, called codons. Each codon specifies a specific amino acid, and the ribosome adds the corresponding amino acid to the growing polypeptide chain. This process continues until a stop codon is reached, at which point the polypeptide is complete.
It's worth noting that in eukaryotic cells, the process of protein synthesis begins in the nucleus, where the mRNA is transcribed from DNA. The mRNA then moves to the cytoplasm, where it is translated into a protein. This is in contrast to prokaryotic cells, where transcription and translation occur in the same location, the cytoplasm.
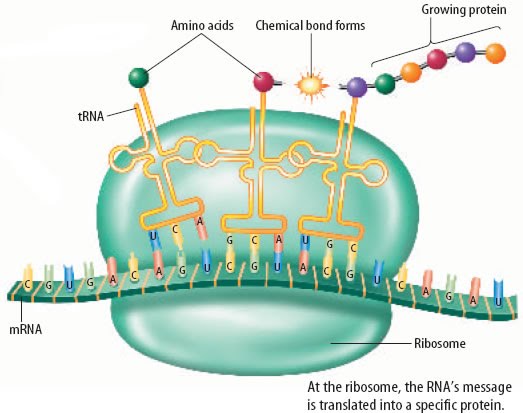
Source: Google Sites
In Prokaryotes
In prokaryotic organisms, the process of transcription and translation occurs simultaneously. This is in contrast to eukaryotic cells, where transcription occurs in the nucleus, and the mRNA must be transported to the cytoplasm for translation. 🚲
During transcription in prokaryotes, the DNA double helix is unwound and one strand of the DNA, known as the template strand, is used as a template to synthesize a complementary RNA molecule. As the RNA polymerase moves along the template strand, it adds nucleotides to the growing RNA molecule. At the same time, ribosomes bind to the mRNA and begin translation.
This simultaneous transcription and translation allows prokaryotes to quickly respond to changes in their environment and produce the necessary proteins in a timely manner. This also allows prokaryotes to produce multiple copies of the same protein at once, increasing efficiency and allowing for rapid growth and reproduction.
The process of simultaneous transcription and translation in prokaryotes is known as co-transcriptional translation. This process is possible because the mRNA is synthesized in a continuous fashion, and the ribosomes bind to the mRNA as soon as it is synthesized, thus there is no need for the mRNA to be transported to the cytoplasm.
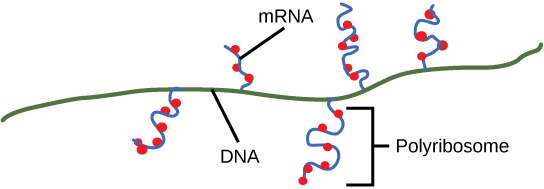
Source: Lumen Learning
Translation is a complex process that involves multiple sequential steps and requires energy in order to be completed. The three main (sequential) steps of translation are initiation, elongation, and termination.
Image courtesy of BCcampus.
Initiation
Initiation occurs when the rRNA in the ribosome interacts with the mRNA at the start codon.
Initiation is the first step in translation and involves the binding of a specific initiator tRNA and the small and large ribosomal subunit to the mRNA. This forms the initiation complex, which recognizes the start codon (usually AUG) on the mRNA and positions the tRNA with its amino acid at the P site (peptidyl site) on the ribosome.
Elongation
tRNA brings the amino acid as specified by the mRNA codons.
Elongation is the second step in translation, and it involves the addition of amino acids to the growing polypeptide chain. This is done by the transfer RNAs (tRNAs) that carry specific amino acids. The tRNA in the A site (aminoacyl site) brings in the next amino acid, and the ribosome catalyzes the formation of a peptide bond between the amino acid in the P site and the incoming amino acid in the A site. The ribosome then moves along the mRNA, bringing the next codon in the A site, and the process repeats.
Termination
Termination is the final step in translation and it involves the release of the polypeptide from the ribosome. This is done by the recognition of one of the three stop codons (UAG, UGA, or UAA) by a release factor. The release factor binds to the stop codon and causes the polypeptide to be released from the ribosome. The ribosome, mRNA, and tRNAs are then free to be recycled for another round of translation. The energy required for translation comes from the hydrolysis of adenosine triphosphate (ATP) and guanosine triphosphate (GTP). The energy from these molecules is used to drive the conformational changes in the ribosome and tRNAs that are necessary for peptide bond formation and for the movement of the ribosome along the mRNA. 🏆
Features of Translation
To be more specific, translation is a fundamental process that converts the genetic information encoded in mRNA into a functional protein. The salient features of translation include: ⚙️
a. Translation is initiated when the rRNA in the ribosome interacts with the mRNA at the start codon. The start codon is usually AUG and the binding of the ribosome to the start codon initiates the translation process.
b. The sequence of nucleotides on the mRNA is read in triplets called codons. Each codon is a sequence of three nucleotides that specifies a specific amino acid.
c. Each codon encodes a specific amino acid, which can be deduced by using a genetic code chart. The genetic code is the set of rules by which the sequence of nucleotides in DNA and RNA is translated into the sequence of amino acids in proteins. The genetic code is nearly universal, meaning that most amino acids are encoded by more than one codon.
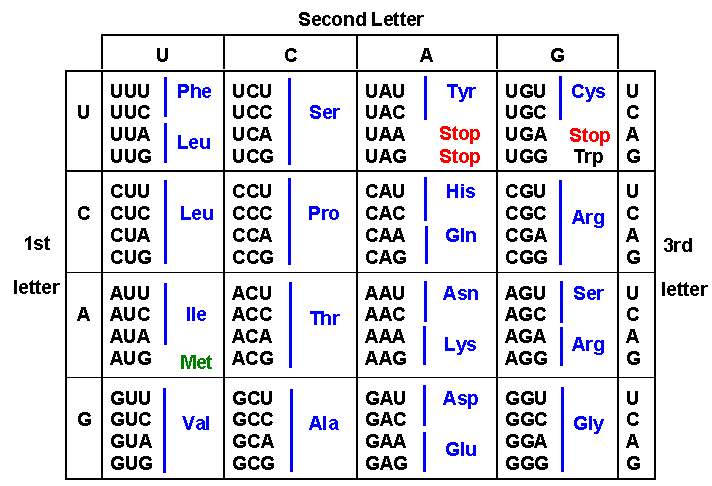
Source: Furman University
d. Nearly all living organisms use the same genetic code, which is evidence for the common ancestry of all living organisms. This suggests that the genetic code is a product of evolution and has been conserved across different species.
e. tRNA brings the correct amino acid to the correct place specified by the codon on the mRNA. The tRNA is a small RNA molecule that carries an amino acid at one end and a specific sequence at the other end called the anticodon. The anticodon is complementary to the codon on the mRNA and this allows the correct tRNA to bind to the correct codon.
f. The amino acid is transferred to the growing polypeptide chain. The ribosome catalyzes the formation of a peptide bond between the amino acid in the P site and the incoming amino acid in the A site.
g. The process continues along the mRNA until a stop codon is reached. The stop codon is a sequence of three nucleotides that signals the end of translation.
h. The process terminates by release of the newly synthesized polypeptide/protein. The release of the protein from the ribosome is mediated by release factors that recognize the stop codon and promote the release of the protein from the ribosome.
A Special Case: Retroviruses
Retroviruses are a unique class of viruses that possess the ability to reverse the flow of genetic information. Unlike other viruses, which use DNA as the genetic material and replicate through transcription and translation, retroviruses use RNA as the genetic material and replicate through a process called reverse transcription. This process is catalyzed by an enzyme called reverse transcriptase, which converts the viral RNA genome into DNA.
The process of reverse transcription begins when the viral RNA genome enters the host cell. Once inside, the viral RNA genome binds to the reverse transcriptase enzyme, which begins to copy the viral RNA genome into DNA. This process is error-prone and can lead to mutations in the viral DNA genome. The newly synthesized viral DNA genome then enters the host cell's nucleus, where it can integrate into the host genome.
Once integrated into the host genome, the viral DNA genome is transcribed into viral RNA, which is then translated into viral proteins. The viral proteins, along with the viral RNA and reverse transcriptase, then assemble to form new viral particles, which can then exit the host cell and infect other cells.
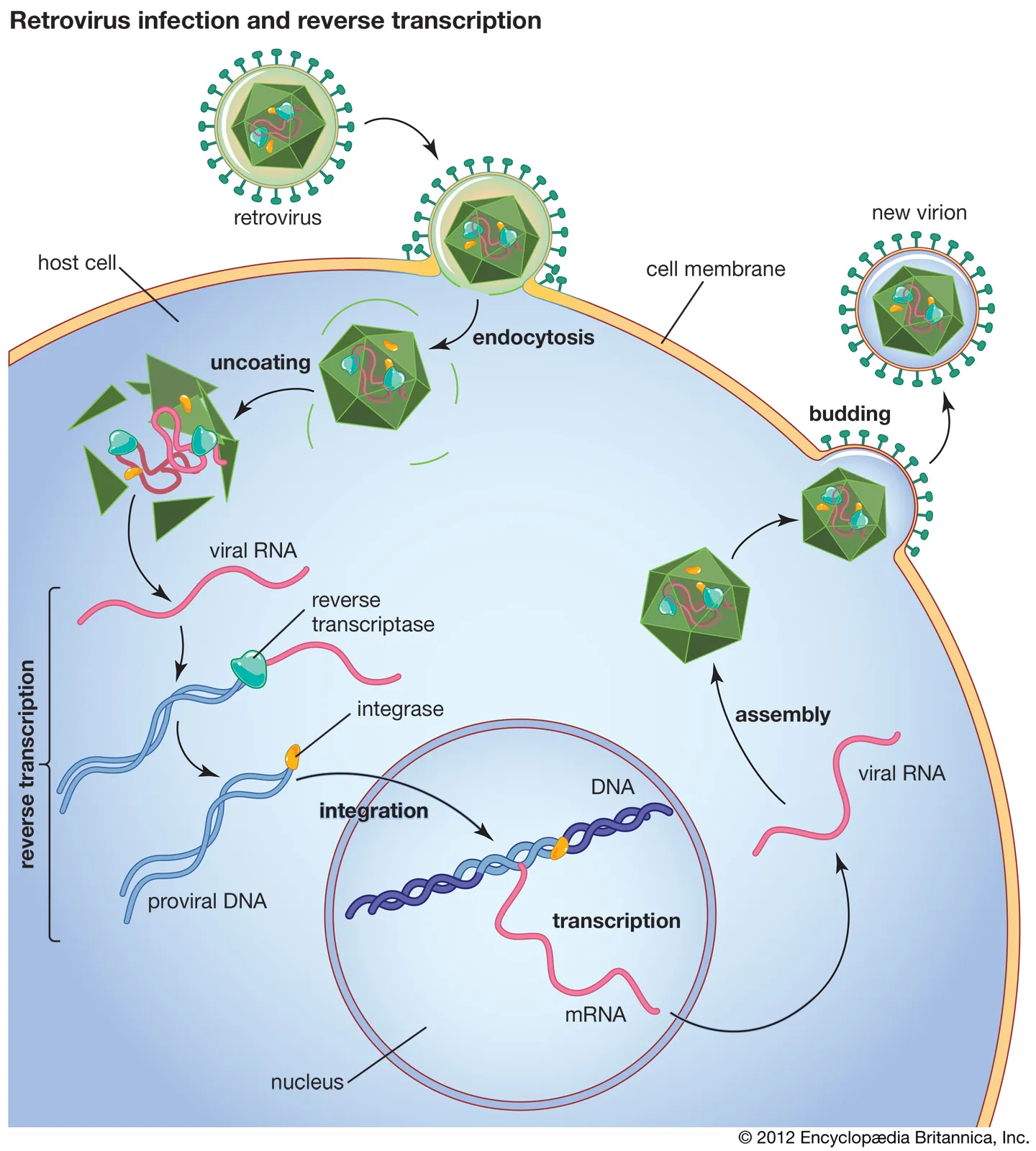
Source: Encyclopedia Britannica
This alternate flow of genetic information in retroviruses is a special case, and it is also what makes them unique and challenging to control. The ability of the viral DNA genome to integrate into the host genome can lead to long-term viral persistence and the development of viral-associated diseases, such as AIDS caused by HIV. 🦠
Check out the AP Bio Unit 6 Replays or watch the 2021 Unit 6 Cram
© 2024 Fiveable Inc. All rights reserved.